Two-phase Hair Image Synthesis by Self-Enhancing Generative Model
Haonan Qiu1 Chuan Wang2 Hang Zhu1 Xiangyu Zhu1 Jinjin Gu1 Xiaoguang Han1
1CUHK (Shenzhen) 2Megvii Technology
Accepted by Computer Graphics Forum, Pacific Graphics 2019
arXiv https://arxiv.org/pdf/1902.11203
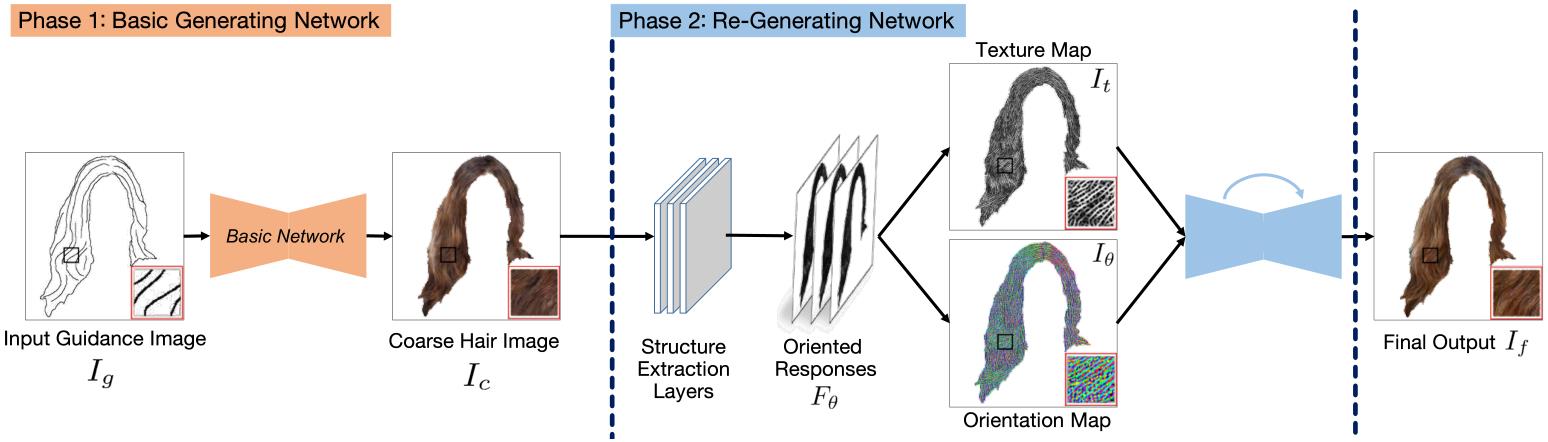 Figure: The architecture of our framework is composed of two phases.
Figure: The architecture of our framework is composed of two phases.
Abstract
Generating plausible hair image given limited guidance, such as sparse sketches or low-resolution image, has been made possible with the rise of Generative Adversarial Networks (GANs). Traditional image-to-image translation networks can generate recognizable results, but finer textures are usually lost and blur artifacts commonly exist. In this paper, we propose a two-phase generative model for high-quality hair image synthesis. The two-phase pipeline first generates a coarse image by an existing image translation model, then applies a re-generating network with self-enhancing capability to the coarse image. The self-enhancing capability is achieved by a proposed differentiable layer, which extracts the structural texture and orientation maps from a hair image. Extensive experiments on two tasks, Sketch2Hair and Hair Super-Resolution, demonstrate that our approach is able to synthesize plausible hair image with finer details, and reaches the state-of-the-art.
Downloads
|
Bibtex
@article{qiu2019two,
title={Two-phase Hair Image Synthesis by Self-Enhancing Generative Model},
author={Qiu, Haonan and Wang, Chuan and Zhu, Hang and Zhu, Xiangyu and Gu, Jinjin and Han, Xiaoguang},
journal={arXiv preprint arXiv:1902.11203},
year={2019}
}